

Data Scientists Falling in Love with Julia: A New Era in Programming
Julia has experienced significant growth in popularity within the data science community in recent years. This high-level, high-performance programming language was specifically designed for numerical and scientific computing, making it well-suited for data science applications. Julia’s appeal stems from its speed, ease of use, and ability to integrate seamlessly with other languages such as Python and R.
Thank you for reading this post, don't forget to subscribe!As the field of data science evolves and demands for more efficient tools increase, Julia has emerged as a strong contender. Its rise can be attributed to several factors, including its active and growing user base comprised of data scientists, researchers, and developers who value its flexibility and performance. Julia’s open-source nature has also contributed to its widespread adoption, allowing for continuous improvement and collaboration within the community.

The language’s ecosystem of packages and libraries tailored for data science has expanded, making Julia an attractive option for professionals seeking to optimize their data analysis and modeling processes. As a result, Julia has established itself as a powerful tool in the data science landscape, offering a combination of performance, ease of use, and versatility that appeals to a wide range of users in the field.
Advantages of Julia for Data Science

Intuitive Syntax for Efficient Development
Julia’s syntax is another significant advantage, closely resembling mathematical notation. This makes it easier for data scientists to express their ideas and algorithms in a natural and readable format, reducing the time and effort required for development and debugging. Additionally, Julia’s multiple dispatch feature enables more flexible and expressive code, allowing data scientists to write concise and elegant solutions to complex problems.
Seamless Interoperability with Other Languages
Julia’s seamless interoperability with languages like Python, R, and C provides data scientists with access to a wide range of existing libraries and tools. This allows for easy integration of Julia into existing workflows and facilitates collaboration with colleagues who may be using different programming languages.
A Compelling Choice for Data Science
Overall, the advantages of Julia for data science are clear, making it a compelling choice for those looking to enhance their productivity and performance in data analysis and modeling.
How Julia is Changing the Landscape of Programming for Data Scientists
Julia is revolutionizing the landscape of programming for data scientists by offering a unique combination of performance, productivity, and flexibility. Its high-level syntax and dynamic typing make it easy to write and maintain code, while its speed and efficiency enable data scientists to tackle more complex problems and larger datasets. This has led to a shift in the way data scientists approach their work, allowing them to explore new possibilities and push the boundaries of what is achievable in data analysis and modeling.
Furthermore, Julia’s emphasis on parallel and distributed computing has opened up new opportunities for data scientists to leverage the power of modern hardware architectures. With built-in support for parallelism and distributed computing, Julia enables data scientists to take full advantage of multi-core processors and clusters, leading to significant improvements in performance and scalability. This has the potential to transform the way data scientists approach computationally intensive tasks, allowing them to tackle larger problems and achieve results more quickly.
Additionally, Julia’s growing ecosystem of packages and libraries tailored for data science is expanding the possibilities for what can be achieved with the language. From machine learning and statistical analysis to visualization and optimization, Julia offers a wide range of tools that empower data scientists to explore new techniques and methodologies. As a result, Julia is changing the landscape of programming for data scientists by providing a platform that encourages innovation, collaboration, and exploration in the field of data science.
Julia’s Impact on Data Science Workflow and Productivity
| Metrics | Data Science Workflow | Productivity Impact |
|---|---|---|
| Performance | Julia’s high performance allows for faster data processing and analysis | Significantly improves productivity by reducing processing time |
| Language Flexibility | Julia’s ability to integrate with other languages and libraries enhances the data science workflow | Increases productivity by providing access to a wide range of tools and resources |
| Community Support | Active Julia community provides resources, packages, and support for data science projects | Boosts productivity by offering a supportive ecosystem for development |
| Parallel Computing | Julia’s built-in support for parallel computing enables efficient processing of large datasets | Improves productivity by enabling concurrent processing and analysis |
Julia’s impact on data science workflow and productivity is significant, as it enables data scientists to work more efficiently and effectively. The language’s speed and performance allow for faster computation and analysis of large datasets, reducing the time required for experimentation and iteration. This leads to quicker insights and decision-making, ultimately improving the productivity of data scientists and the overall efficiency of data science workflows.

Furthermore, Julia’s intuitive syntax and multiple dispatch feature contribute to improved productivity by enabling data scientists to write cleaner, more expressive code. This reduces the time spent on debugging and maintenance, allowing for faster development and iteration of algorithms and models. Additionally, Julia’s seamless interoperability with other languages such as Python and R facilitates collaboration with colleagues and the integration of existing tools into the data science workflow, further enhancing productivity.
Moreover, Julia’s emphasis on parallelism and distributed computing has a profound impact on data science workflow by enabling data scientists to leverage modern hardware architectures more effectively. This allows for faster execution of computationally intensive tasks and the ability to scale up to larger problems, ultimately improving the efficiency of data science workflows. Overall, Julia’s impact on data science workflow and productivity is undeniable, as it provides data scientists with the tools they need to work more efficiently and effectively in their pursuit of insights and solutions.
Overcoming Challenges and Barriers in Adopting Julia for Data Science

While Julia offers numerous advantages for data science, there are also challenges and barriers that need to be overcome in its adoption. One such challenge is the learning curve associated with transitioning to a new programming language. Data scientists who are already proficient in languages such as Python or R may find it challenging to adapt to Julia’s syntax and features, requiring time and effort to become proficient in the language.
Another barrier to adopting Julia for data science is the availability of libraries and tools compared to more established languages such as Python or R. While Julia’s ecosystem is growing rapidly, it may still lack some of the specialized libraries and packages that data scientists rely on for their work. This can make it difficult for data scientists to transition fully to Julia without sacrificing access to essential tools and resources.
Furthermore, there may be organizational barriers to adopting Julia within a team or company, such as concerns about compatibility with existing systems or the need for retraining staff. Overcoming these challenges requires a concerted effort to provide training and support for data scientists looking to transition to Julia, as well as investment in expanding the language’s ecosystem of libraries and tools tailored for data science. Despite these challenges, the benefits of adopting Julia for data science are clear, making it worth the effort to overcome these barriers.
With its exceptional speed, intuitive syntax, and emphasis on parallelism, Julia offers significant advantages that can improve the efficiency and effectiveness of data science workflows. By addressing these challenges head-on, organizations can unlock the full potential of Julia for their data science endeavors.
The Future of Julia in Data Science and Programming
Expanding Ecosystem of Packages and Libraries
As the language’s ecosystem of packages and libraries tailored for data science continues to expand, Julia will offer even greater possibilities for innovation and exploration in the field.
Scalable Solutions for Big Data
Furthermore, Julia’s emphasis on parallelism and distributed computing aligns with the growing demand for scalable solutions in data science. As organizations continue to grapple with increasingly large volumes of data and complex computational tasks, Julia’s ability to leverage modern hardware architectures will become increasingly valuable.
A Collaborative Effort for Advancements
Additionally, as more data scientists become proficient in Julia and contribute to its ecosystem, the language will continue to evolve and improve. This collaborative effort will lead to further advancements in tools and techniques tailored for data science, solidifying Julia’s place as a powerful platform for innovation in the field. Overall, the future of Julia in data science looks bright, with the potential to reshape the way data scientists approach their work and achieve insights from complex datasets.
Tips for Data Scientists Transitioning to Julia
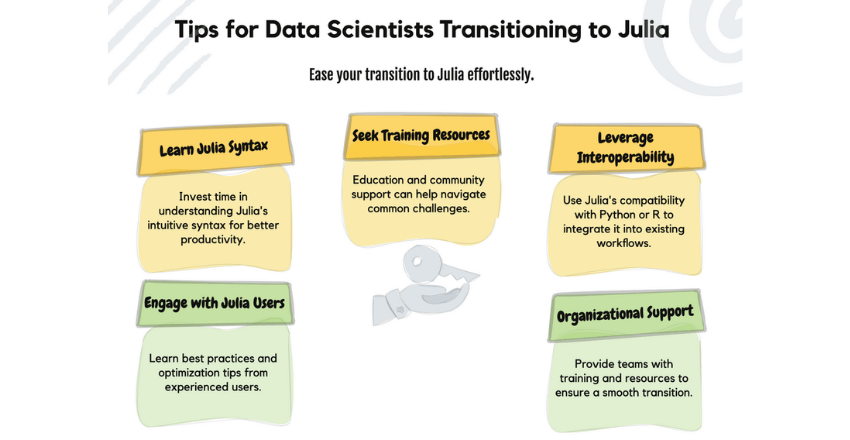
For data scientists looking to transition to Julia, there are several tips that can help ease the process and maximize the benefits of adopting the language. First and foremost, investing time in learning Julia’s syntax and features is essential for a smooth transition. While there may be a learning curve associated with adapting to a new programming language, becoming proficient in Julia’s intuitive syntax will ultimately lead to improved productivity and efficiency in data science workflows.
Additionally, leveraging Julia’s interoperability with other languages such as Python or R can help ease the transition by allowing data scientists to gradually integrate Julia into their existing workflows. This can be particularly beneficial when transitioning existing code or leveraging specialized libraries that may not yet be available in Julia’s ecosystem. Furthermore, seeking out training resources or communities dedicated to Julia can provide valuable support during the transition process.
Engaging with other users who have experience with Julia can offer insights into best practices, tips for optimization, and solutions to common challenges that arise when adopting a new language. Finally, organizations looking to adopt Julia for data science should consider investing in training and support for their teams to ensure a smooth transition. Providing resources for learning Julia’s syntax and features can help accelerate proficiency among data scientists while also fostering a culture of collaboration around the language.
Transitioning to Julia for data science requires dedication and effort but offers significant advantages in terms of speed, productivity, and flexibility. By following these tips and investing in training and support, data scientists can maximize the benefits of adopting Julia as a powerful tool for tackling complex problems in data analysis and modeling.